
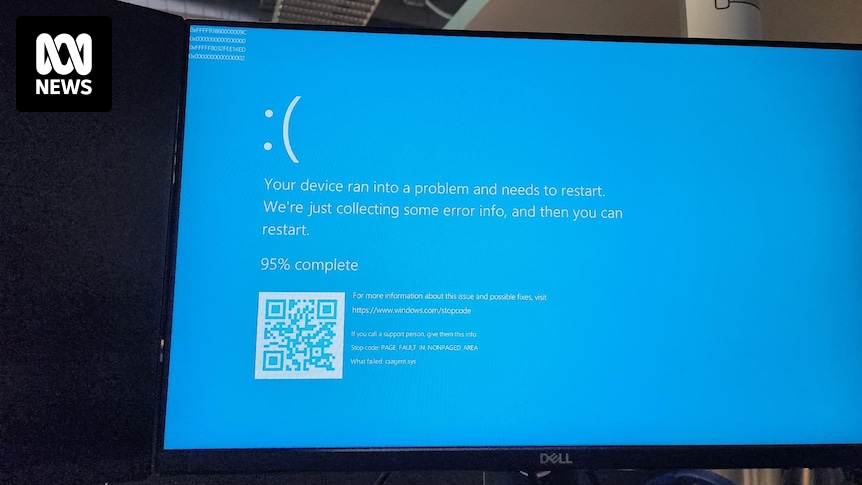
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
never do updates on a Friday.
deleted by creator
And especially now the work week has slimmed down where no one works on Friday anymore
Excuse me, what now? I didn’t get that memo.
Yeah it’s great :-) 4 10hr shifts and every weekend is a 3 day weekend
Is the 4x10 really worth the extra day off? Tbh I’m not sure it would work very well for me… I find just one 10-hour day to be kinda draining, so doing that 4 times a week every week feels like it might just cancel out any benefits of the extra day off.
I am very used to it so I don’t find it draining. I tried 5x8 once and it felt more like working an extra day than getting more time in the afternoon. If that makes sense. I also start early around 7am, so I am only staying a little later than other people
deleted by creator
I changed jobs because the new management was all “if I can’t look at your ass you don’t work here” and I agreed.
I now work remotely 100% and it’s in the union contract with the 21vacation days and 9x9 compressed time and regular raises. The view out my home office window is partially obscured by a floofy cat and we both like it that way.
I’d work here until I die.
Yep, anything done on Friday can enter the world on a Monday.
I don’t really have any plans most weekends, but I sure as shit don’t plan on spending it fixing Friday’s fuckups.
And honestly, anything that can be done Monday is probably better done on Tuesday. Why start off your week by screwing stuff up?
We have a team policy to never do externally facing updates on Fridays, and we generally avoid Mondays as well unless it’s urgent. Here’s roughly what each day is for:
- Monday - urgent patches that were ready on Friday; everyone WFH
- Tuesday - most releases; work in-office
- Wed - fixing stuff we broke on Tuesday/planning the next release; work in-office
- Thu - fixing stuff we broke on Tuesday, closing things out for the week; WFH
- Fri - documentation, reviews, etc; WFH
If things go sideways, we come in on Thu to straighten it out, but that almost never happens.
Actually I was not even joking. I also work in IT and have exactly the same opinion. Friday is for easy stuff!
You posted this 14 hours ago, which would have made it 4:30 am in Austin, Texas where Cloudstrike is based. You may have felt the effect on Friday, but it’s extremely likely that the person who made the change did it late on a Thursday.
Never update unless something is broken.
This is fine as long as you politely ask everyone on the Internet to slow down and stop exploiting new vulnerabilities.
I think vulnerabilities found count as “something broken” and chap you replied to simply did not think that far ahead hahah
For real - A cyber security company should basically always be pushing out updates.
always pushing out updates
Notes: Version bump: Eric is a twat so I removed his name from the listed coder team members on the about window.
git push --force
leans back in chair productive day, productive day indeed
git commit -am "Fixed" && git push --force
Exactly. You don’t know what the vulnerabilities are, but the vendors pushing out updates typically do. So stay on top of updates to limit the attack surface.
Major releases can wait, security updates should be pushed as soon as they can be proven to not break prod.
That’s advice so smart you’re guaranteed to have massive security holes.
BTW, I use Arch.
If it was Arch you’d update once every 15 minutes whether anything’s broken or not.
I use Tumbleweed, so I only get updates once/day, twice if something explodes. I used to use Arch, so my update cycle has lengthened from 1-2x/day to 1-2x/week, which is so much better.
gets two update notifications
Ah, must be explosion Wednesday
I really like the tumbleweed method, seems like the best compromise between arch and debian style updates.
I think a lot of what (open)SUSE does is pretty solid. For example, microOS is a fantastic compromise between a stable base and a rolling userspace, and I think a lot of people would do well to switch to it from Leap. I currently use Leap for my NAS, but I do plan to switch to microOS.
This is AV, and even possible that it is part of definitions (for example some windows file deleted as false positive). You update those daily.
>Make a kernel-level antivirus
>Make it proprietary
>Don’t test updates… for some reason??Reading into the updates some more… I’m starting to think this might just destroy CloudStrike as a company altogether. Between the mountain of lawsuits almost certainly incoming and the total destruction of any public trust in the company, I don’t see how they survive this. Just absolutely catastrophic on all fronts.
If all the computers stuck in boot loop can’t be recovered… yeah, that’s a lot of cost for a lot of businesses. Add to that all the immediate impact of missed flights and who knows what happening at the hospitals. Nightmare scenario if you’re responsible for it.
This sort of thing is exactly why you push updates to groups in stages, not to everything all at once.
Looks like the laptops are able to be recovered with a bit of finagling, so fortunately they haven’t bricked everything.
And yeah staged updates or even just… some testing? Not sure how this one slipped through.
Not sure how this one slipped through.
I’d bet my ass this was caused by terrible practices brought on by suits demanding more “efficient” releases.
“Why do we do so much testing before releases? Have we ever had any problems before? We’re wasting so much time that I might not even be able to buy another yacht this year”
At least nothing like this happens in the airline industry
Certainly not! Or other industries for that matter. It’s a good thing executives everywhere aren’t just concentrating on squeezing the maximum amount of money out of their companies and funneling it to themselves and their buddies on the board.
Sure, let’s “rightsize” the company by firing 20% of our workforce (but not management!) and raise prices 30%, and demand that the remaining employees maintain productivity at the level it used to be before we fucked things up. Oh and no raises for the plebs, we can’t afford it. Maybe a pizza party? One slice per employee though.
One of my coworkers, while waiting on hold for 3+ hours with our company’s outsourced helpdesk, noticed after booting into safe mode that the Crowdstrike update had triggered a snapshot that she was able to roll back to and get back on her laptop. So at least that’s a potential solution.
Testing in production will do that
Not everyone is fortunate enough to have a seperate testing environment, you know? Manglement has to cut cost somewhere.
Manglement is the good term lmao
Agreed, this will probably kill them over the next few years unless they can really magic up something.
They probably don’t get sued - their contracts will have indemnity clauses against exactly this kind of thing, so unless they seriously misrepresented what their product does, this probably isn’t a contract breach.
If you are running crowdstrike, it’s probably because you have some regulatory obligations and an auditor to appease - you aren’t going to be able to just turn it off overnight, but I’m sure there are going to be some pretty awkward meetings when it comes to contract renewals in the next year, and I can’t imagine them seeing much growth
Nah. This has happened with every major corporate antivirus product. Multiple times. And the top IT people advising on purchasing decisions know this.
Yep. This is just uninformed people thinking this doesn’t happen. It’s been happening since av was born. It’s not new and this will not kill CS they’re still king.
At my old shop we still had people giving money to checkpoint and splunk, despite numerous problems and a huge cost, because they had favourites.
Don’t most indemnity clauses have exceptions for gross negligence? Pushing out an update this destructive without it getting caught by any quality control checks sure seems grossly negligent.
I think you’re on the nose, here. I laughed at the headline, but the more I read the more I see how fucked they are. Airlines. Industrial plants. Fucking governments. This one is big in a way that will likely get used as a case study.
The London Stock Exchange went down. They’re fukd.
Yeah saw that several steel mills have been bricked by this, that’s months and millions to restart
Got a link? I find it hard to believe that a process like that would stop because of a few windows machines not booting.
a few windows machines with controller application installed
That’s the real kicker.
Those machines should be airgapped and no need to run Crowdstrike on them. If the process controller machines of a steel mill are connected to the internet and installing auto updates then there really is no hope for this world.
There is no unsafer place than isolated network. AV and xdr is not optional in industry/healthcare etc.
I work in an environment where the workstations aren’t on the Internet there’s a separate network, there’s still a need for antivirus and we were hit with bsod yesterday
then there really is no hope for this world.
I don’t know how to tell you this, but…
But daddy microshoft says i gotta connect the system to the internet uwu
No, regulatory auditors have boxes that need checking, regardless of the reality of the technical infrastructure.
There are a lot of heavy manufacturing tools that are controlled and have their interface handled by Windows under the hood.
They’re not all networked, and some are super old, but a more modernized facility could easily be using a more modern version of Windows and be networked to have flow of materials, etc more tightly integrated into their systems.
The higher precision your operation, the more useful having much more advanced logs, networked to a central system, becomes in tracking quality control.
Imagine if after the fact, you could track a set of .1% of batches that are failing more often and look at the per second logs of temperature they were at during the process, and see that there’s 1° temperature variance between the 30th to 40th minute that wasn’t experienced by the rest of your batches. (Obviously that’s nonsense because I don’t know anything about the actual process of steel manufacturing. But I do know that there’s a lot of industrial manufacturing tooling that’s an application on top of windows, and the higher precision your output needs to be, the more useful it is to have high quality data every step of the way.)
deleted by creator
explain to the project manager with crayons why you shouldn’t do this
Can’t; the project manager ate all the crayons
rolling out an update to production that there was clearly no testing
Or someone selected “env2” instead of “env1” (#cattleNotPets names) and tested in prod by mistake.
Look, it’s a gaffe and someone’s fired. But it doesn’t mean fuck ups are endemic.
Why is it bad to do on a Friday? Based on your last paragraph, I would have thought Friday is probably the best week day to do it.
Most companies, mine included, try to roll out updates during the middle or start of a week. That way if there are issues the full team is available to address them.
deleted by creator
And hence the term read-only Friday.
Was it not possible for MS to design their safe mode to still “work” when Bitlocker was enabled? Seems strange.
I’m not sure what you’d expect to be able to do in a safe mode with no disk access.
Don’t we blame MS at least as much? How does MS let an update like this push through their Windows Update system? How does an application update make the whole OS unable to boot? Blue screens on Windows have been around for decades, why don’t we have a better recovery system?
Crowdstrike runs at ring 0, effectively as part of the kernel. Like a device driver. There are no safeguards at that level. Extreme testing and diligence is required, because these are the consequences for getting it wrong. This is entirely on crowdstrike.
This didn’t go through Windows Update. It went through the ctowdstrike software directly.
What lawsuits do you think are going to happen?
They can have all the clauses they like but pulling something like this off requires a certain amount of gross negligence that they can almost certainly be held liable for.
Whatever you say my man. It’s not like they go through very specific SLA conversations and negotiations to cover this or anything like that.
I forgot that only people you have agreements with can sue you. This is why Boeing hasn’t been sued once recently for their own criminal negligence.
👌👍
😔💦🦅🥰🥳
Forget lawsuits, they’re going to be in front of congress for this one
For what? At best it would be a hearing on the challenges of national security with industry.
The amount of servers running Windows out there is depressing to me
I’ve had my PC shut down for updates three times now, while using it as a Jellyfin server from another room. And I’ve only been using it for this purpose for six months or so.
I can’t imagine running anything critical on it.
Windows server, the OS, runs differently from desktop windows. So if you’re using desktop windows and expecting it to run like a server, well, that’s on you. However, I ran windows server 2016 and then 2019 for quite a few years just doing general homelab stuff and it is really a pain compared to Linux which I switched to on my server about a year ago. Server stuff is just way easier on Linux in my experience.
It doesn’t have to, though. Linux manages to do both just fine, with relatively minor compromises.
Expecting an OS to handle keeping software running is not a big ask.
Yup, I use Linux to run a Jellyfin server, as well as a few others things. The only problem is that the CPU I’m using (Ryzen 1st gen) will crash every couple weeks or so (known hardware fault, I never bothered to RMA), but that’s honestly not that bad since I can just walk over and restart it. Before that, it ran happily on an old Phenom II from 2009 for something like 10 years (old PC), and I mostly replaced it because the Ryzen uses a bit less electricity (enough that I used to turn the old PC off at night; this one runs 24/7 as is way more convenient).
So aside from this hardware issue, Linux has been extremely solid. I have a VPS that tunnels traffic into my Jellyfin and other services from outside, and it pretty much never goes down (I guess the host reboots it once a year or something for hardware maintenance). I run updates when I want to (when I remember, which is about monthly), and it only goes down for like 30 sec to reboot after updates are applied.
So yeah, Linux FTW, once it’s set up, it just runs.
not that bad since I can just walk over and restart it.
You can try to use watchdog to automatically restart on crashes. Or go through RMA.
I could, but it’s a pretty rare nuisance. I’d rather just replace the CPU than go through RMA, a newer gen CPU is quite inexpensive, I could probably get by with a <$100 CPU since anything AM4 should work (I have an X370 with support for 5XXX series CPUs).
I’m personally looking at replacing it with a much lower power chip, like maybe something ARM. I just haven’t found something that would fit well since I need 2-4 SATA (PCIe card could work), 16GB+ RAM, and a relatively strong CPU. I’m hopeful that with ARM Snapdragon chips making their way to laptops and RISC-V getting more available, I’ll find something that’ll fit that niche well. Otherwise, I’ll just upgrade when my wife or I upgrade, which is what I usually do.
I just haven’t found something that would fit well since I need 2-4 SATA (PCIe card could work), 16GB+ RAM, and a relatively strong CPU.
4 SATA, 8GB RAM is easy to find. What do you need 16 gigs for? Compiling Gentoo?
Star64 for ARM and Quartz64 for RV.
big ask.
Off the car lot, we say ‘request’. But good on you for changing careers.
I really have no idea why you think your choice of wording would be relevant to the discussion in any way, but OK…
removed by mod
Wow dude you’re so cool. I bet that made you feel so superior. Everyone on here thinks you are so badass.
I do as well!
Wow and the most predictable reply too? Poor guy. Better luck next time.
Not judging, but why wouldn’t you run Linux for a server?
Because I only have one PC (that I need for work), and I can’t be arsed to cock around with dual boot just to watch movies. Especially when Windows will probably break that at some point.
Can you use Linux as main OS then? What do you need your computer to do?
I need to run windows software that makes other windows software, that will be run on our customers (who pay us quite well) PCs that also run windows.
Plus gaming. I’m not switching my primary box to Linux at any point. If I get a mini server, that will probably ruin Linux.
I need to run windows software that makes other windows software, that will be run on our customers (who pay us quite well) PCs that also run windows.
Mingw, but whatever. Maybe there is somethong mingw can’t do.
Plus gaming. I’m not switching my primary box to Linux at any point.
Unless it is Apex and some other worst offenders or you use GPU from the only company actively hostile to linux, gaming is fine.
I dunno, but doesn’t like a quarter of the internet kinda run on Azure?
so 40% of azure crashes a quarter of the internet…
I guess Spotify was running on the other 40%, as many other services
doesn’t like a quarter of the internet kinda run on Azure?
Said another way, 3/4 of the internet isn’t on Unsure cloud blah-blah.
And azure is - shhh - at least partially backed by Linux hosts. Didn’t they buy an AWS clone and forcibly inject it with money like Bobby Brown on a date in the hopes of building AWS better than AWS like they did with nokia? MS could be more protectively diverse than many of its best customers.
The four multinational corporations I worked at were almost entirely Windows servers with the exception of vendor specific stuff running Linux. Companies REALLY want that support clause in their infrastructure agreement.
I’ve worked as an IT architect at various companies in my career and you can definitely get support contracts for engineering support of RHEL, Ubuntu, SUSE, etc. That isn’t the issue. The issue is that there are a lot of system administrators with “15 years experience in Linux” that have no real experience in Linux. They have experience googling for guides and tutorials while having cobbled together documents of doing various things without understanding what they are really doing.
I can’t tell you how many times I’ve seen an enterprise patch their Linux solutions (if they patched them at all with some ridiculous rubberstamped PO&AM) manually without deploying a repo and updating the repo treating it as you would a WSUS. Hell, I’m pleasantly surprised if I see them joined to a Windows domain (a few times) or an LDAP (once but they didn’t have a trust with the Domain Forest or use sudoer rules…sigh).
The issue is that there are a lot of system administrators with “15 years experience in Linux” that have no real experience in Linux.
Reminds me of this guy I helped a few years ago. His name was Bob, and he was a sysadmin at a predominantly Windows company. The software I was supporting, however, only ran on Linux. So since Bob had been a UNIX admin back in the 80s they picked him to install the software.
But it had been 30 years since he ever touched a CLI. Every time I got on a call with him, I’d have to give him every keystroke one by one, all while listening to him complain about how much he hated it. After three or four calls I just gave up and used the screenshare to do everything myself.
AFAIK he’s still the only Linux “sysadmin” there.
“googling answers”, I feel personally violated.
/s
To be fare, there is not reason to memorize things that you need once or twice. Google is tool, and good for Linux issues. Why debug some issue for few hours, if you can Google resolution in minutes.
I’m not against using Google, stack exhange, man pages, apropos, tldr, etc. but if you’re trying to advertise competence with a skillset but you can’t do the basics and frankly it is still essentially a mystery to you then youre just being dishonest. Sure use all tools available to you though because that’s a good thing to do.
Just because someone breathed air in the same space occasionally over the years where a tool exists does not mean that they can honestly say that those are years of experience with it on a resume or whatever.
Just because someone breathed air in the same space occasionally over the years where a tool exists does not mean that they can honestly say that those are years of experience with it on a resume or whatever.
Capitalism makes them to.
Agreed. If you are not incompetent, you will remember the stuff that you use often. You will know exactly where to look to refresh your memory for things you use infrequently, and when you do need to look something up, you will understand the solution and why it’s correct. Being good at looking things up, is like half the job.
Companies REALLY want that support clause in their infrastructure agreement.
RedHat, Ubuntu, SUSE - they all exist on support contracts.
Where did you think Microsoft was getting all (hyperbole) of their money from?
I know i was really surprised how many there are. But honestly think of how many companies are using active directory and azure
Yeah my plans of going to sleep last night were thoroughly dashed as every single windows server across every datacenter I manage between two countries all cried out at the same time lmao
crowdstrike sent a corrupt file with a software update for windows servers. this caused a blue screen of death on all the windows servers globally for crowdstrike clients causing that blue screen of death. even people in my company. luckily i shut off my computer at the end of the day and missed the update. It’s not an OTA fix. they have to go into every data center and manually fix all the computer servers. some of these severs have encryption. I see a very big lawsuit coming…
CrowdStrike Holdings, Inc. is an American cybersecurity technology company based in Austin, Texas.
Never trust a texan
https://www.theregister.com/ has a series of articles on what’s going on technically.
Latest advice…
There is a faulty channel file, so not quite an update. There is a workaround…
-
Boot Windows into Safe Mode or WRE.
-
Go to C:\Windows\System32\drivers\CrowdStrike
-
Locate and delete file matching “C-00000291*.sys”
-
Boot normally.
-
I was quite surprised when I heard the news. I had been working for hours on my PC without any issues. It pays off not to use Windows.
A lot of people I work with were affected, I wasn’t one of them. I had assumed it was because I put my machine to sleep yesterday (and every other day this week) and just woke it up after booting it. I assumed it was an on startup thing and that’s why I didn’t have it.
Our IT provider already broke EVERYTHING earlier this month when they remote installed" Nexthink Collector" which forced a 30+ minute CHKDSK on every boot for EVERYONE, until they rolled out a fix (which they were at least able to do remotely), and I didn’t want to have to deal with that the week before I go in leave.
But it sounds like it even happened to running systems so now I don’t know why I wasn’t affected, unless it’s a windows 10 only thing?
Our IT have had some grief lately, but at least they specified Intel 12th gen on our latest CAD machines, rather than 13th or 14th, so they’ve got at least one win.
Irrelevant but I keep reading “crowd strike” as “counter strike” and it’s really messing with me
I see a lot of hate ITT on kernel-level EDRs, which I wouldn’t say they deserve. Sure, for your own use, an AV is sufficient and you don’t need an EDR, but they make a world of difference. I work in cybersecurity doing Red Teamings, so my job is mostly about bypassing such solutions and making malware/actions within the network that avoids being detected by it as much as possible, and ever since EDRs started getting popular, my job got several leagues harder.
The advantage of EDRs in comparison to AVs is that they can catch 0-days. AV will just look for signatures, a known pieces or snippets of malware code. EDR, on the other hand, looks for sequences of actions a process does, by scanning memory, logs and hooking syscalls. So, if for example you would make an entirely custom program that allocates memory as Read-Write-Execute, then load a crypto dll, unencrypt something into such memory, and then call a thread spawn syscall to spawn a thread on another process that runs it, and EDR would correlate such actions and get suspicious, while for regular AV, the code would probably look ok. Some EDRs even watch network packets and can catch suspicious communication, such as port scanning, large data extraction, or C2 communication.
Sure, in an ideal world, you would have users that never run malware, and network that is impenetrable. But you still get at avarage few % of people running random binaries that came from phishing attempts, or around 50% people that fall for vishing attacks in your company. Having an EDR increases your chances to avoid such attack almost exponentionally, and I would say that the advantage it gives to EDRs that they are kernel-level is well worth it.
I’m not defending CrowdStrike, they did mess up to the point where I bet that the amount of damages they caused worldwide is nowhere near the amount damages all cyberattacks they prevented would cause in total. But hating on kernel-level EDRs in general isn’t warranted here.
Kernel-level anti-cheat, on the other hand, can go burn in hell, and I hope that something similar will eventually happen with one of them. Fuck kernel level anti-cheats.
Yep, this is the stupid timeline. Y2K happening to to the nuances of calendar systems might have sounded dumb at the time, but it doesn’t now. Y2K happening because of some unknown contractor’s YOLO Friday update definitely is.
I’m so exhausted… This is madness. As a Linux user I’ve busy all day telling people with bricked PCs that Linux is better but there are just so many. It never ends. I think this is outage is going to keep me busy all weekend.
Stop running production services on M$. There is a better backend OS.


















